Data Quality
Data Quality / Data Cleansing
One of the keys to a successful data conversion is having high data quality. In order to achieve high data quality, the process of data cleansing is necessary. To perform data cleansing, we rely on the data quality rules identified during the analysis phase to develop a series of automated SQL scripts that will run to identify data cleansing issues. When the data quality rules have been run against the data, they are reported in the CMT in the “Error Frequencies” section. The image below shows some sample data quality error reported on the CROS project:
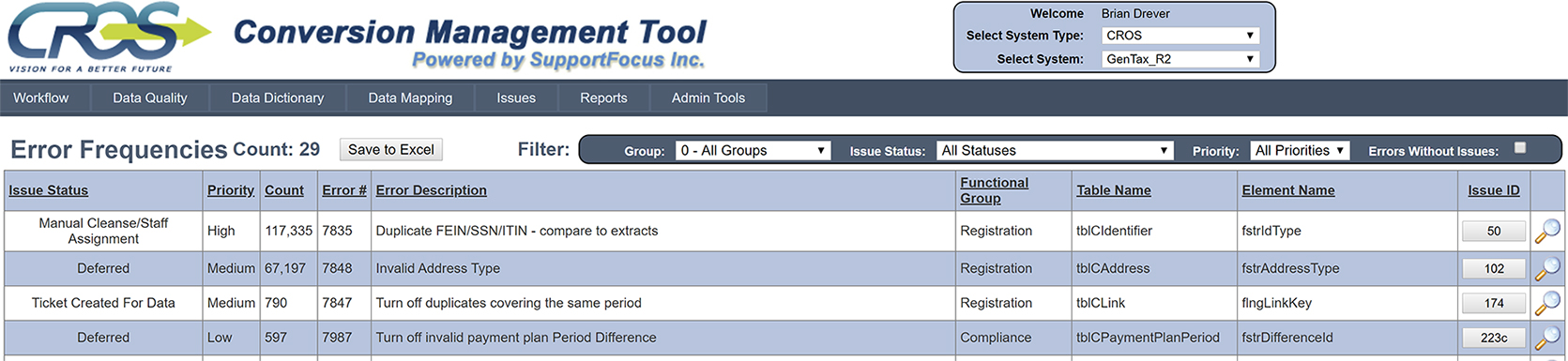
If a converted or staged data element or table “fails” a rule, then that data and the rules are analyzed in detail and changes are made to the maps if necessary, to accommodate a previously unknown data issue, or the data is flagged for legacy cleanup, or both.
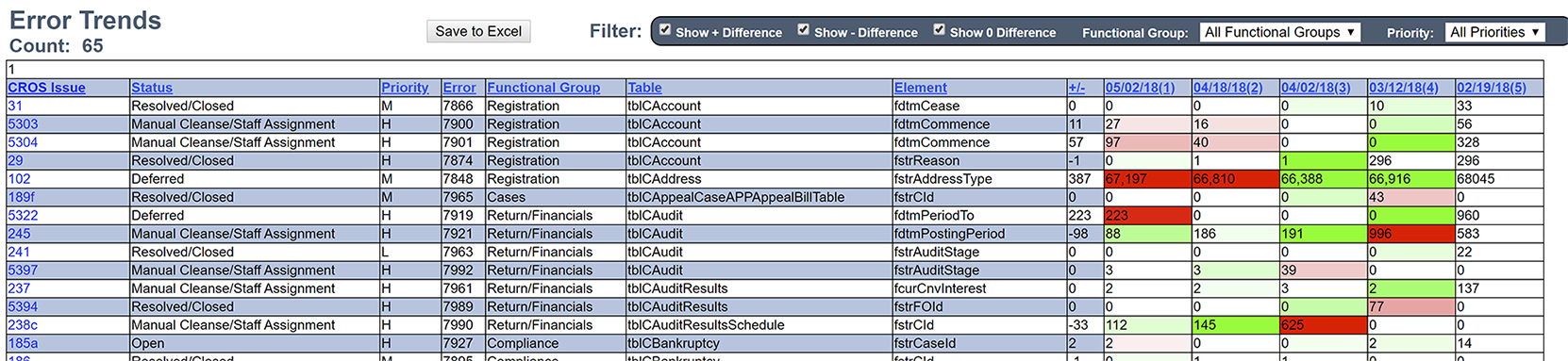
Each conversion iteration updates the picture of data “cleanliness”, and the CMT contains a color-based trend page that makes spotting data anomalies a straight forward process. Error trends that are either staying static or increasing are targeted for additional resources, or other remediation. A sample error trend page is shown below. As error counts go down, the shading of green is used to indicate positive progress. if error counts go up, they are shaded red to stand out as needing to be further addressed.